


Ever since data dedupe appliances hit the data storage market, they have become a regular fixture in any enterprise backup solution. Filling the gap between spinning disks and the virtual tape library, these appliances provide not only a better access to backup data, but also drive cost savings by efficiently storing only the unique data from backup images.
In general, data dedupe engines can remove duplicate data anywhere in the dataset, and are particularly effective in two use cases:
- In virtual environments where multiple VMs are instantiated using one template and each of the VMs share the same boot image, a dedupe engine can effectively keep only one copy of the boot image when you backup these VMs.
- During backups, backup engines backup the same file at regular intervals of time. You save the amount of storage used, as the dedupe engines only keep the modifications between two backups no matter how minor they are.
Here is how a typical dedupe appliance works:
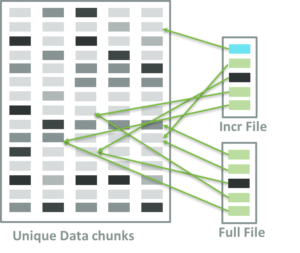
In the above diagram, full and incremental backups share all blocks except for the one marked in blue. The dedupe appliance only keeps these blocks of unique data. Each block has a signature or a hash that is based on one of SHA algorithms. The file in the dedupe appliance is a sequence of signatures that correspond to data blocks of the file. You can think of them as pointers to the actual data or block indexes in inode. The complexity of this bookkeeping, the size of the unique block and fixed/variable size of the block differs from implementation to implementation, but you get the idea.
The Way We Look at Data Dedupe Has Shifted
As recently as a few years ago, data dedupe was a radical idea when storage was expensive, enterprises were faced with data explosion and tapes were too slow and cumbersome to handle. However, with the evolution of new technologies and practices, along with the ever-shifting sand dunes of the technology landscape, trends like this are only good for that moment before the relevance diminishes. Obviously, data dedupe is not immune to these technology shifts. Today, cloud is one big factor to consider when designing and implementing new generation data centers and the dedupe technology can only hinder your data center evolution into cloud.
Here is why: under the covers, deduplication engines require a great deal of bookkeeping.
- The dedupe applicance must maintain reference count on blocks.
- When a new file references a unique data block, the reference count is incremented.
- When a file is deleted and some of the blocks are no longer referenced, delete the blocks as part of garbage collection.
- Uniqueness of the data block is determined by the signature of the data based on SHA algorithms. Every time new data is written, the dedupe appliance needs to do lot of data crunching to weed out duplicate data.
Generating a complete file from the deduplicated file is called hydration. The process of removing duplicate blocks in a file is called dehydration. Hydrating a file takes more storage, and modifying dehydrated files takes additional storage and repeated modifications to them, putting enormous strain on a dedupe appliance. For example, synthetic full backups that most backup engines support these days are required to modify a dehydrated file. Data dedupe works very similarly to compression algorithms, as there is a trade-off between the amount of storage savings vs the dedupe algorithm overhead. If the data does not have enough duplication, additional bookkeeping and hash calculation overhead may severely impact the overall dedupe appliance performance.
Additionally, the unique data blocks and the hash calculations are internal to the dedupe appliance. For example, let’s assume that each incremental delta is 10GB. If we take 1TB of production data with one full backup and 30 incremental backups, then the total storage consumed in the deduplication appliance is around 1.3 TB. The impressive cost savings of 28.7TB is only real if all of the backups of the data are kept on the appliance. However, if you were to migrate your backups to a different media or to a cloud storage – such as AWS S3 – all of these savings disappear because you are forced to hydrate all 30 incrementals, exploding the amount of storage needed for all backups. At this point, you are a captive audience to your dedupe appliance and are limited by your IT agility.
The TrilioVault Approach
TrilioVault is a pure software-only solution that leverages industry standard data formats and tools to create the next generation backup engine. Scaling in capacity and performance, TrilioVault prevents any bottlenecks from forming. TrilioVault can be configured to use any standard NFSv3/v4 file share, Swift object store, or S3 compatible object store for backup repository.
TrilioVault took a different approach to storage savings than the one implemented in data dedupe appliances. We choose a backup image format that is capable of supporting deduplication itself without the complexity of custom hardware. The mapping of unique blocks is encoded in the image format making “dedupe” functionality portable between media and platforms.
Let’s go back to the example of 10TB of data that has 30 backups with one full and the rest incrementals. In the following diagram, the full backup is at the bottom and the incrementals are layered in the order in which the backups were taken. The image format that TrilioVault chose support sparse files, but for the sake of argument, we assume that production data is fully provisioned. Each one of the backup files are regular files with incrementals containing only the blocks that were modified from previous backups.

Benefits of the TrilioVault Approach
There are multiple advantages to this approach to backup.
- All images, including full and incremental, are regular files on the file system.
- Each incremental image only includes the delta changes from the previous backup.
- Each incremental can be accessed as a full image. Access to a block in an incremental is traversed from that incremental to full image until the allocated block is found in the latest image.
- There is no vendor specific encoding. All block references are encoded in the image format without the need for a custom appliance to maintain hash to unique block mappings.
- In the above example, tar ball of /var/triliovault/backupjob1 includes full and incremental images without losing the storage savings and versioning information.
- Since these are regular files, the files can be easily copied using standard Linux tools from one media to another media. For example, a tar file can be copied to AWS S3 including all point in time copies without the need to hydrate the images or without losing versioning.
- If there is ever a need to recover the backup on a different target, say AWS VPC, these images can be converted to EC2 instances, EBS volumes etc with some basic scripting.
- Since the backup images can be retrieved using standard Linux tools without the need to signing a long term maintenance contract with the hardware vendor, you are future proofing your backups.
Business Agility
In summary, TrilioVault’s approach to deduplication offers you the agility that business applications require in today’s cloud era. It is a pure software solution based on industry standards that provides the freedom from custom hardware. Though TrilioVault backup images may not offer the deduplication that traditional dedupe vendors offers due to their large data set, TrilioVault offers a nice trade-off between application agility and storage efficiencies.
