
Importance of Cloud Backup Solutions for OpenStack
If you’re using any sort of cloud infrastructure, it’s absolutely imperative that you employ cloud-native backup to help support and extend your cloud. I know, I know–you’ve already got dozens of vendors set up with seemingly compelling Band-Aids for your latest crop of problems, but I promise you: you don’t want the Band-Aid. Here’s why.
You’d like to think your cloud is considered safe, but data loss happens. It happens a lot: hardware malfunctioned during a firmware update; someone fat-fingered a configuration; your server room was dampened by a leaky pipe. The list goes on.
No matter the reason, without a cloud-native backup solution, you’re risking losing your data forever. You might think that data redundancy will shield you–but if there is corrupted or misconfigured data/VMs, then that error is then replicated across your systems, and you’re left high and dry. What you need is to be able to go back to a specific point in time, and to have fast access to reliably restore your entire workload to that state when you need to.
As more and more organizations embrace private cloud architectures, the need for specialized cloud backup solutions tailored to OpenStack has become increasingly vital. Solutions from Trilio provide a range of features and functionalities that ensure data protection and recovery within the cloud-native environment.

Overview of Dedicated Cloud Backup Solutions for OpenStack
There are lots of legacy tools on the market. From time to time, cloud admins ask themselves if it makes sense to use the tools they already have. Sure, it’s possible, but you’re severely crippling the functionality of your backup and restore operations by doing that.
By force-fitting an outdated approach onto a modern cloud, administrators typically must settle for disruptive, agent-based solutions that lack multi-tenancy and only store data in proprietary formats that require their tools to unlock. Often, normal day-to-day changes in the cloud environment require extensive, ongoing manual intervention just to keep the records current and functional.
To add color to this “legacy vs. cloud native” debate, here are a couple of simple analogies:
- How do you compare Windows 3.1 with Android? After all, both are multitasking operating systems with a graphical user interface. You and I know that the similarities end there: Windows 3.1 is not meant for mobile and hasn’t evolved since the 1980s. We can technically port Windows 3.1 to mobile devices, but that doesn’t make it a mobile operating system. Likewise, legacy backup solutions cannot be ported to address cloud backup needs.
- Would you race a Formula 1 circuit with the state-of-the-art car but with a 1960-era pit crew? The only time it worked was in Disney’s Cars but in real life, it is not a wise decision. When your cloud is agile and elastic, your backup solution should keep up with your cloud. This is where cloud native solutions differentiate from legacy backup solutions.
Cloud backup solutions specifically designed for OpenStack offer features that guarantee reliable data protection. Leveraging the architecture of OpenStack, Trilio’s solutions enable backups and swift intelligent recovery, making them an ideal choice for cloud-native platforms.
Emphasizing the Significance of Data Backup in a Cloud Native Environment
Typical descriptions of “cloud native” applications talk to points of power and scale. Yes, those things are true, but that’s not really what we’re talking about here. When we reference “cloud native” backup, we’re talking about a solution that’s been built specifically for OpenStack clouds. These types of solutions not only enable performance but reduce time spent on management activities and make data easy to back up and restore. You shouldn’t have to dedicate that much time to these areas.
At Trilio, we subscribe to a cloud-native backup philosophy (more on that later…). That’s large because we’ve seen firsthand that, although clouds are often complex and unwieldy, a good backup strategy makes recovery pretty simple… and it can drastically reduce the time it takes to get environments back up and running in the event of a disaster. After all, time is money.
In an environment where applications are distributed across multiple nodes and rely on granular microservices, ensuring data protection becomes paramount. The dynamic nature of applications necessitates a backup solution capable of adapting to changing workloads while consistently safeguarding data.
Cloud backup solutions tailored for OpenStack, like those provided by Trilio, offer the required flexibility and scalability to protect data in these environments. By offering automated features for scheduling, monitoring, and managing backups, Trilio and similar solutions guarantee the protection of data even as the cloud-native environment evolves.
- Automated Backup Scheduling: Cloud backup solutions designed for OpenStack often provide built-in capabilities for scheduling backups. This empowers organizations to automate their backup processes effortlessly. By defining policies tailored to their needs businesses can ensure that data is regularly backed up without requiring manual intervention.
- Monitoring and Management: These solutions offer monitoring and management functionalities that enable organizations to keep track of their backup status and efficiently restore data whenever necessary. Through dashboards and reporting tools administrators can effectively. Monitor the backup infrastructure performance ensuring that data protection remains up to date at all times.
- Efficient Recovery: In case of data loss or a disaster scenario cloud backup solutions for OpenStack enable organizations to swiftly recover their data with efficiency. These solutions provide flexible recovery options that allow administrators to restore files or entire applications as needed. With scalability and flexibility, at hand, minimal downtime is ensured while maintaining operations.
The significance of safeguarding data in an environment cannot be emphasized enough. By leveraging backup solutions dedicated to OpenStack, such as those offered by Trilio, organizations can fully embrace the scalability and agility offered by cloud-native architectures while guaranteeing the security and recoverability of their valuable data. Trilio’s commitment to providing top-notch backup solutions ensures peace of mind for organizations as they navigate the dynamic landscape of cloud-native computing.
Disaster Recovery and OpenStack
Disaster recovery is an aspect of any IT infrastructure, including OpenStack. As native environments grow more complex and expansive it becomes increasingly important to have strategies in place to ensure uninterrupted business operations during unexpected events.
Understanding the Concept of Disaster Recovery in OpenStack
In the context of OpenStack disaster recovery refers to the process of recovering services and data in the event of a failure. This can encompass hardware failures, software glitches, natural disasters, or even human errors. The primary objective is to minimize downtime, data loss, and operational disruptions.
Within a native backup environment disaster recovery entails replicating data and services across locations or availability zones. This duplication guarantees that if one location experiences issues the system can swiftly switch to a location for operations. Moreover, a comprehensive disaster recovery plan should include safeguards against data corruption, security breaches, and other potential risks.
Best Practices for Implementing Robust Disaster Recovery Strategies
Implementing a disaster recovery strategy in OpenStack necessitates planning and adherence to proven best practices.
Here are some important things to consider:
- Set clear recovery point objectives (RPO) and recovery time objectives (RTO): It’s crucial to determine the amount of data loss and downtime, for your organization. These objectives will serve as a guide for your disaster recovery planning.
- Backup your data: Make sure to create backups of your data and configurations at intervals so that you always have the most recent copies available for recovery. The frequency of backups may vary depending on how critical the data is
- Take advantage of automated mechanisms: Utilize OpenStack’s capabilities, such as those offered by Trilio, to automate failover. Distribute workloads across multiple availability zones. This reduces the need for intervention during disaster recovery and ensures optimal use of resources.
- Test your disaster recovery plan: It’s important to test your disaster recovery plan to identify any gaps or weaknesses. Simulate different failure scenarios. Evaluate the effectiveness of your recovery procedures.
- Safeguard data integrity and security: Implement measures such as data encryption, integrity checks, access controls, and authentication mechanisms to protect the confidentiality, integrity, and authorized access to your backups.
By following these recommended practices, with the assistance of Trilio’s disaster recovery solutions, you can significantly improve the resilience of your OpenStack environment while minimizing the impact that potential disasters may have. Trilio’s expertise in disaster recovery is invaluable in ensuring the continuity of your business operations in the face of unforeseen events.

Why Cloud Native Matters for Backup Solutions
DevOps Process Integration
These days, any serious cloud implementation includes a robust DevOps process. DevOps and Infrastructure-as-Code (IAC) have become synonymous with cloud life cycle management: DevOps tools help you with configuration management and IAC lets you version control your configuration. Essentially, the life cycle management of the cloud is fully automated, without ever needing manual intervention.
Re-architecting your cloud is easily one of the most challenging tasks in IT. When you choose a backup solution, look for one that adheres to your established cloud management practice. Whether you are deploying a new cloud, scaling a cloud, or upgrading the cloud, your backup solution should be managed by the same processes you implemented for your cloud.
Multi-Tenancy and Self Service
A typical cloud supports hundreds or thousands of tenants who deploy and manage their applications on an ad hoc basis. They have total autonomy (within a given role) to provide the resources they need as they need them, including VMs, networks, and storage from their portal.
Backup, recovery, and management shouldn’t be any different. Each tenant should be able to set the data protection policies that their applications require and manage data retention based on individual application SLAs. Rather than limiting these activities to backup experts (and watching the help desk tickets pile up in the process), OpenStack tenants should be able to log into Horizon and administer their own backup policies at their leisure.
Future-Proofing
Since many OpenStack backup projects are relatively immature, we’ve seen a lot of folks in this space cobble together a custom solution by choosing different technologies from different vendors. In most cases, they end up selecting a backup engine from one vendor, a dedupe hardware appliance from another, and backing up the incompatible solutions separately in their proprietary formats.
Unsurprisingly, this doesn’t typically end favorably. It’s easy enough to tuck them away on a remote server as a literal “backup plan,” but if you need to recover from proprietary formats or just manage them, you will need to have a valid license(s). Forever. That’s astonishingly restrictive.
Distributed Cloud Workloads
Clouds simply aren’t tidy. They tend to have thousands upon thousands of workloads spanning multiple VMs that are using a few dozen variations of network and storage configurations.
But legacy backup solutions are still VM-centric: they’ll only capture a single VM or data volume. So when you apply this legacy backup solution to your cloud with applications distributed among multiple VMs, you simply won’t be able to capture all the critical configuration data associated with those VMs.
Expensive Centralized Management
In the good old days, a central backup administrator was the master of your company’s data universe. They knew each and every application and created custom backup solutions that catered to each. The backup solutions they purchased reflected the keys-to-the-kingdom oligarchy.
In the cloud, there is no central administrator and the cloud administrator is not privy to all the applications that were deployed by all of their many, many tenants. Documenting it would be fruitless, since it changes faster than you Vizio a topology, anyway. In fact, in true cloud environments, cloud administrators cannot access each tenant.
Today, IT departments that force-fit legacy products to create an OpenStack backup solution are walking a dangerous line. It’s simply not correct to assume that your cloud administrator has total and complete access to all tenant applications. Beyond that, it’s unwieldy to centralize backup and recovery activities to a handful of individuals rather than delegating them to the tenants who want control, anyway. Here, it makes sense to keep a lean centralized team and distribute the work across your organization via self-service GUIs.
Related resource- Great Scott…Time Travel For Big Data & OpenStack Made Simple!
That's Why We Implemented a Cloud Native Strategy for Backups at Trilio
At Trilio, we’re frenetic about giving administrators and tenants the right level of access and control in their clouds.
We made a choice two years ago to pursue a cloud-native approach. Building a cloud-native data protection solution was not only a natural first step for our company but almost a necessity for the OpenStack market at large: there just weren’t any enterprise-caliber options available for OpenStack backup today.
Today, TrilioVault remains the only cloud-native backup solution for OpenStack clouds.
Non-Disruptive Backup
- Agentless: TrilioVault Data Movers seamlessly integrate with your DevOps tools like Ansible, Puppet, Chef
- API-driven
- Requires minimal to no changes to your cloud architecture
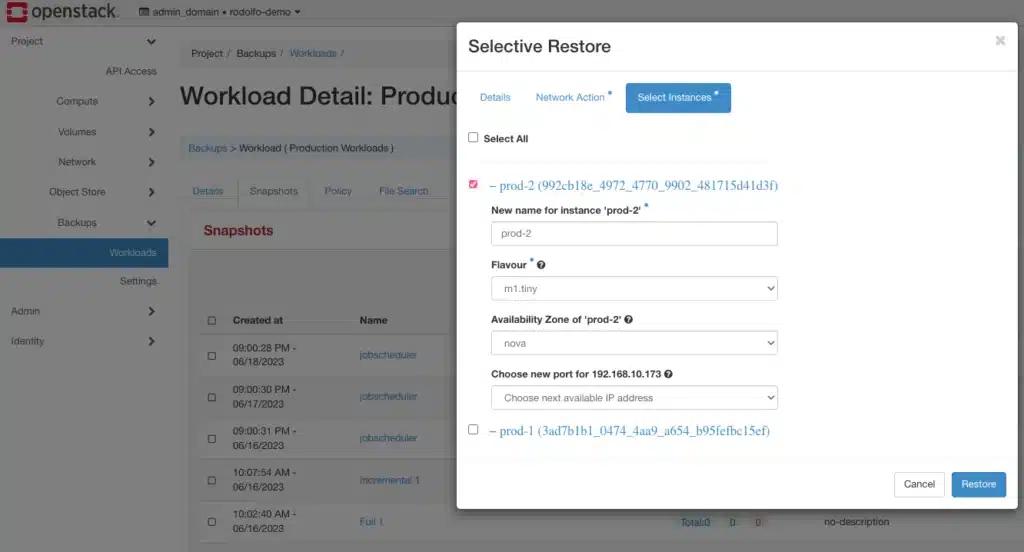
One-Click Restore
- Captures & recovers the entire workload (including applications, security groups, and every configuration detail) to provide a reliable and rapid recovery path no matter how complex
- Forever incremental capture lets tenants set the backup policies on a group of related VMs and forget it until they need to restore from synthetic full images
- Recover in place or to a new place within the same cloud or a new one
Self-Service Management & Control
- Multi-tenant backup and recovery with role-based access controls, so there’s no need for a dedicated backup administrator
- Scales with your cloud software-only solution (so long as the underlying network and backup capacity grow with it)
- Truly OpenStack native: integrates with Keystone, Nova, Horizon, and leading OpenStack distributions, plus backs up to Swift, S3, Ceph, and NFS repositories
- Non-proprietary images via standard Linux QCOW2 file format, so you can manage your data however you’d like
In conclusion
The importance of cloud backup solutions tailored to OpenStack, such as those offered by Trilio, cannot be overstated. These solutions provide robust data protection and recovery features, ensuring the security of valuable data in a cloud-native environment.
Disaster recovery strategies in OpenStack are crucial for minimizing downtime and data loss during unexpected events, with best practices emphasizing clear objectives, regular backups, automation, testing, and data integrity measures.
Additionally, the adoption of a hybrid cloud approach for OpenStack backup combines the strengths of public and private clouds, optimizing scalability, security, and cost efficiency.
Cloud-native backup solutions like Trilio offer the necessary flexibility, scalability, and efficiency for backup and recovery in the dynamic world of cloud computing.
Choosing a cloud-native approach for backups is essential, as legacy solutions often fall short in meeting the unique demands of modern cloud environments, and Trilio’s approach aligns with cloud-native principles, enabling non-disruptive, agentless, and self-service backup and recovery, making it a valuable choice for OpenStack users.




